
























Free Customer Engagement Guides
Join our newsletter for actionable tips and proven strategies to grow your business and engage your customers.
Heads Data Science.Expert in AI, Data & Analytics and awarded 40 under 40 Data Scientists in India.
WhatsApp has quickly become one of the most effective customer engagement channels, with consistently high open and response rates. But
The Indian Premier League (IPL) has evolved into India’s biggest marketing stage, with ~620 million viewers expected in 2026 and
Your team spent six weeks building a re-engagement campaign. You did everything by the playbook. Initially, the open rates looked
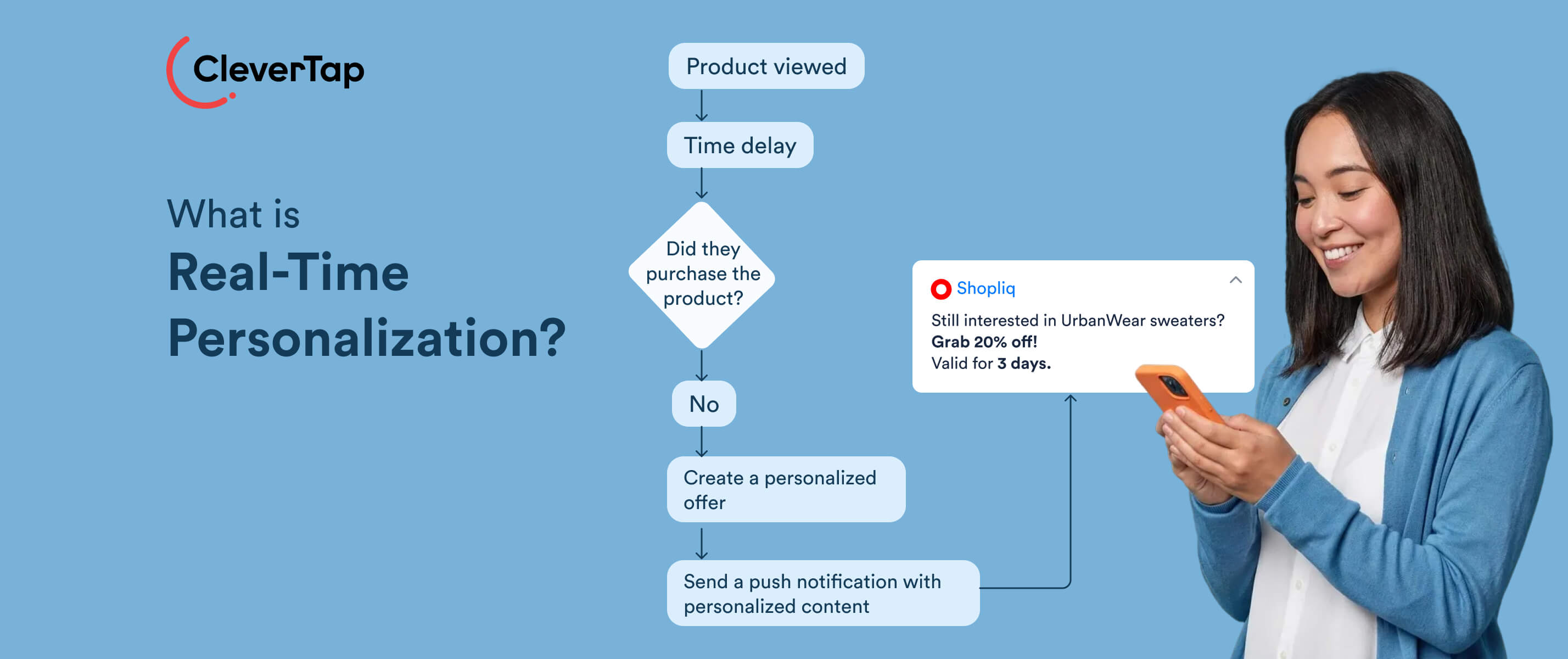
Shoppers move fast. One scans running shoes on your site, drops a premium pair into their cart, then hesitates, perhaps
Easter is a vibrant time of family gatherings, gifting, and springtime celebration, making it a prime opportunity for brands to
La inteligencia artificial (IA) está cambiando la forma en que las empresas de e-commerce interactúan con los clientes y los
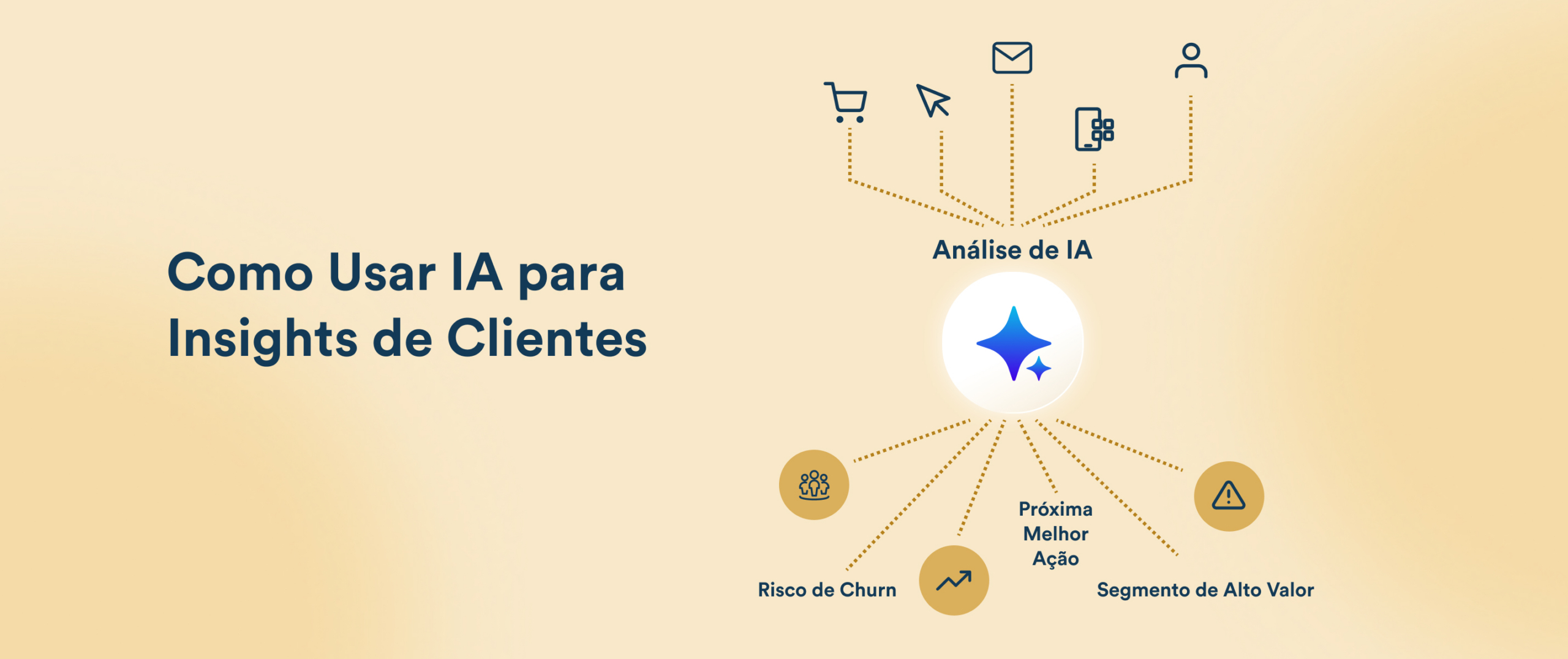
A inteligência artificial (IA) está mudando a forma como as empresas de e-commerce engajam e retêm clientes. Neste guia, vamos
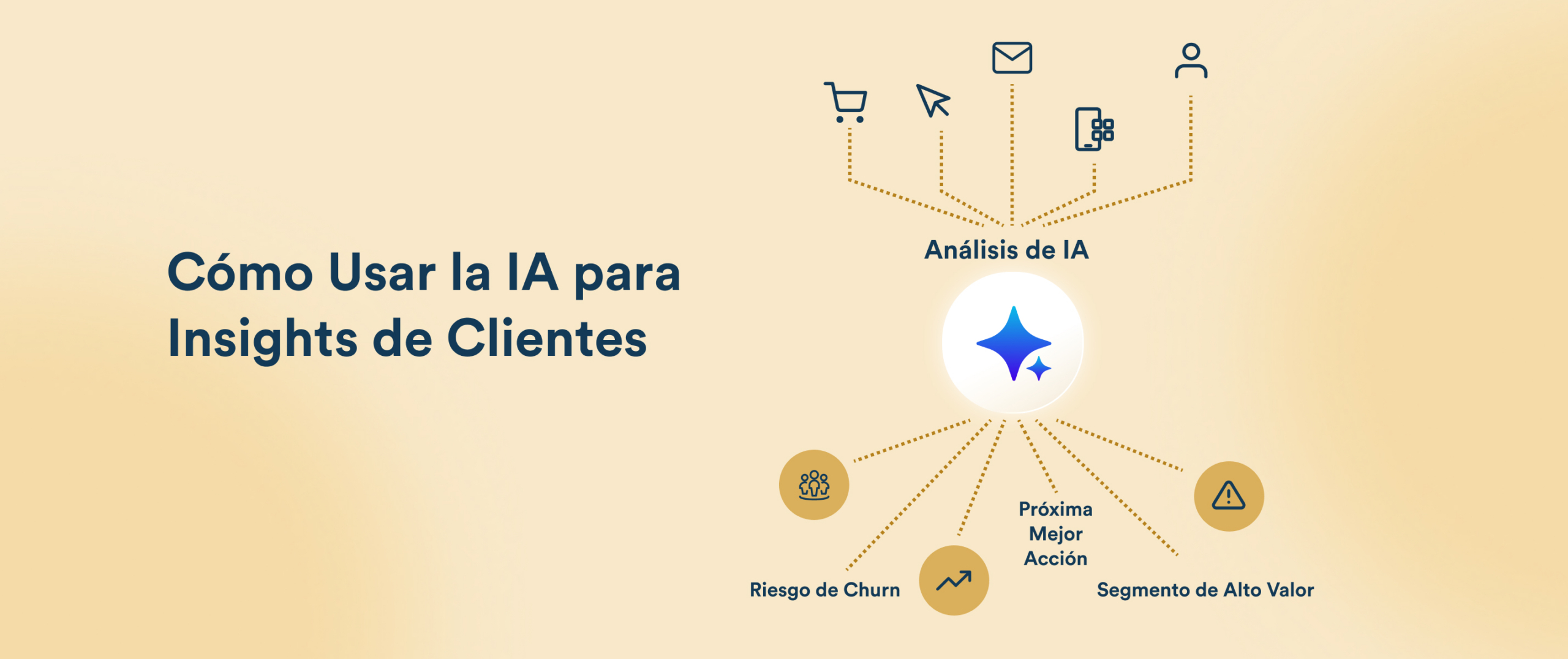
La inteligencia artificial está transformando la manera en que los profesionales de marketing entienden el comportamiento de los clientes y
A inteligência artificial está transformando a forma como os profissionais de marketing entendem e respondem ao comportamento dos clientes. Em
Artificial intelligence is changing how marketers understand and act on customer behavior. Instead of relying only on past reports, teams
Your team spent six weeks building a re-engagement campaign. You did everything by the playbook. Initially, the open rates looked
The role of analytics is rapidly shifting from descriptive dashboards to predictive intelligence in the B2C marketing space. Instead of
Savvy marketers increasingly rely on predictive approaches to gain an edge in a data-driven market. With fragmented customer journeys, shorter
Different types of AI agents have made big promises in marketing when it comes to efficiency and customer experience, with
Traditional automation has long supported marketers by handling repetitive tasks, but it stops at execution. Marketing AI agents, on the
In the era of hyper-personalization, customer engagement relies more than ever on data. Now, as AI pushes the boundaries from
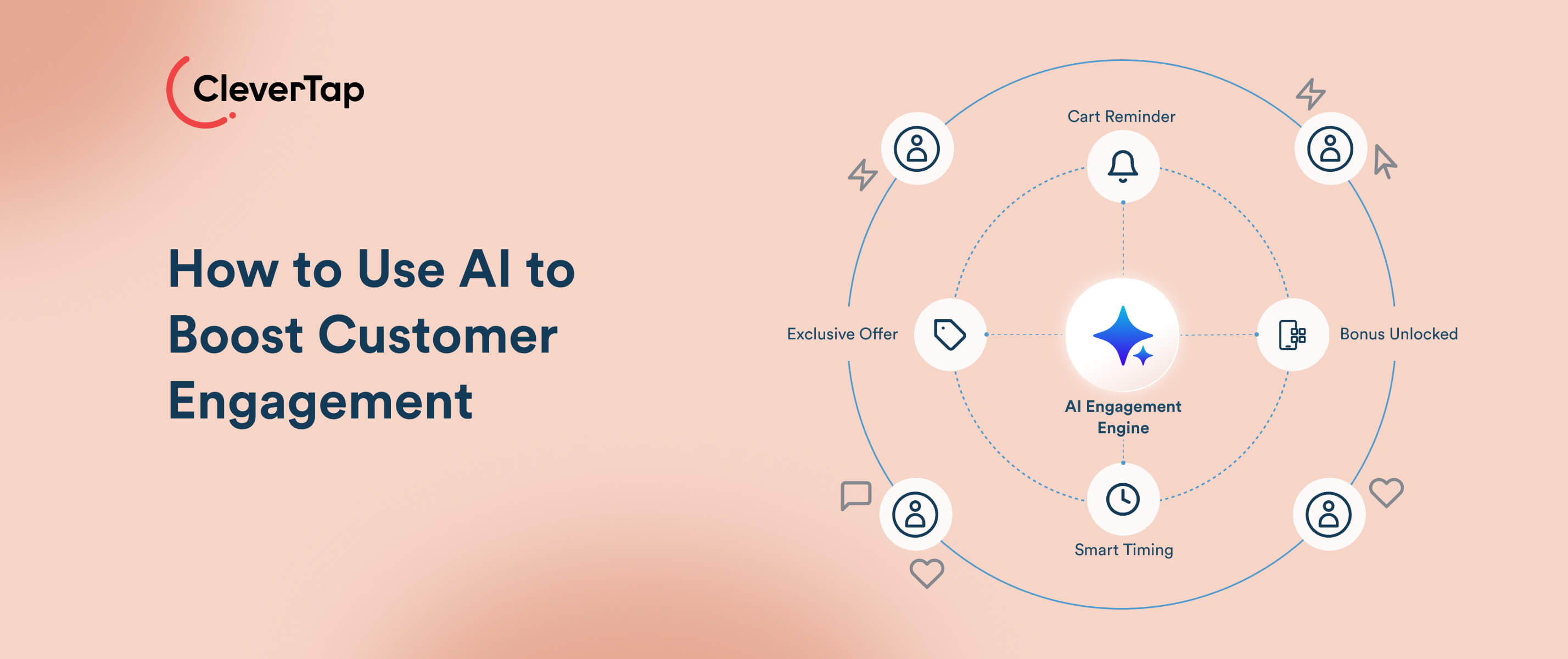
Artificial intelligence (AI) is changing how e-commerce companies engage and retain customers. In this guide, we’ll explore practical ways to
Free Customer Engagement Guides
Join our newsletter for actionable tips and proven strategies to grow your business and engage your customers.
