














Table of Contents
Categories
Most Popular


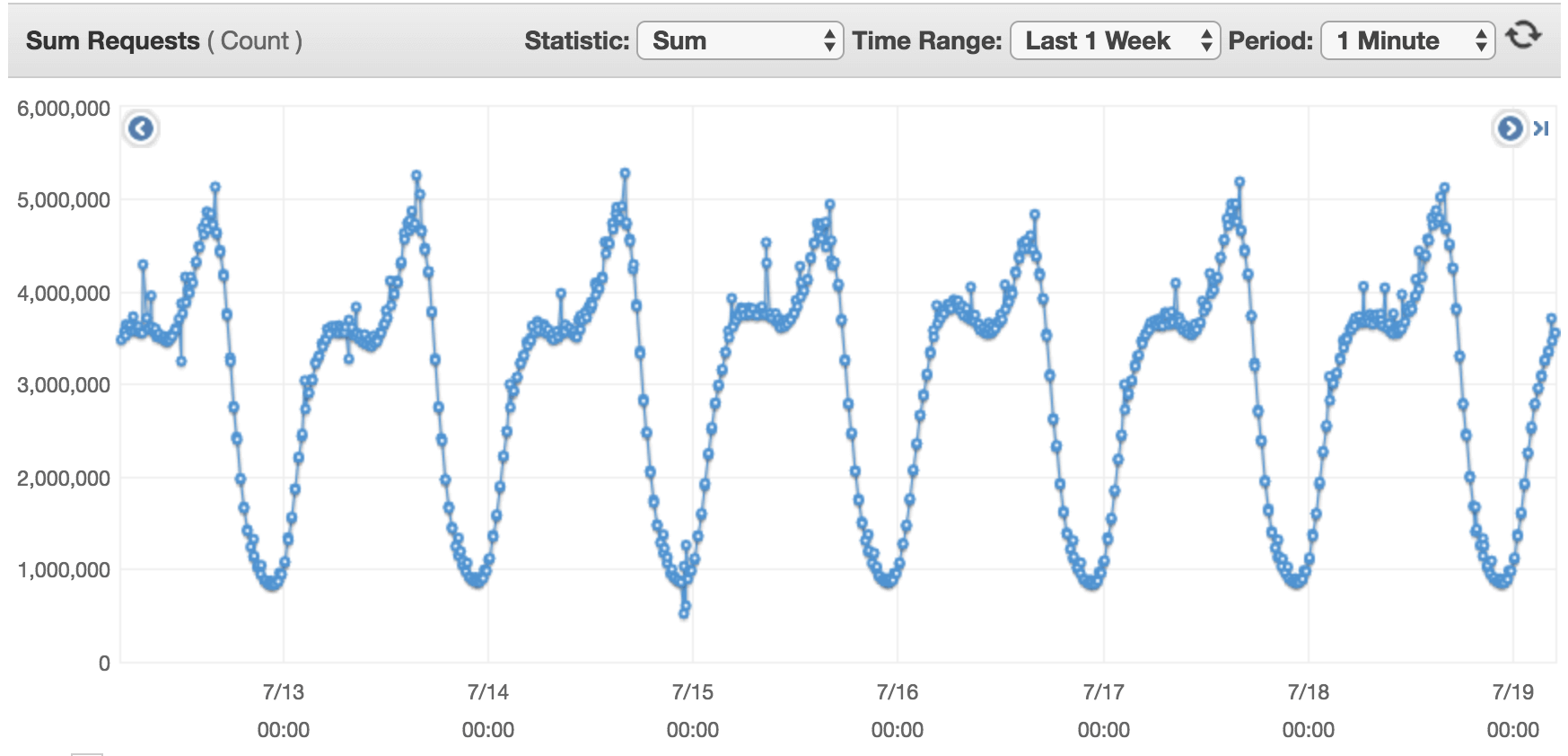
Now that a little more than half of 2017 has gone by, I want to talk about some of infrastructure changes we put in place beginning December 2016, based on our experience of running clevertap.com on AWS for the past three years. These changes were prompted by the requirement to support clevertap.com in multiple geographical data-centers for compliance requirements of some of our large customers and the need be agile. On interesting days, we handle a 4x increase in incoming write traffic, going from 33K req/sec to 166K req/sec within twenty minutes.
Background Context
Most of our AWS infrastructure was setup in May 2014. Back then, I was aware of CloudFormation but didn’t go with it — so it was clickety-click all over the console to setup the components – AutoScaling groups, Launch configurations, ELB, subnets, routes, security groups, etc. Inside the EC2 instance, Puppet was our tool for configuration management. Nagios (also managed by Puppet via exported resources) faithfully monitored everything for us.
Fast forward two years, here’s what we learnt and how we implemented the same infrastructure again.
From Clickety-Click to CloudFormation
When tasked with setting up a parallel data center to support a Fortune 500 customer, there was no way in hell I was going to click all over the console again. Besides, I knew this was the tip of the iceberg. At the rate at which we were growing, more customers would ask for their data to be hosted in geographically local data-centers. We had to have a way to reliably reproduce all of our AWS configuration.
This is when we got really serious about CloudFormation.
Fortunately, the learning curve for CloudFormation is not so steep. Don’t be scared by looking at sample CF templates, especially if you are just beginning with it — they just look really long. If you have used the console and are familiar with AWS concepts, CF just feels like an alternative to clickety-clicks aka infrastructure-as-code. Within my first hour with CF, I had the VPC provisioned. Over the next week, we managed to port all of our AWS resources into a template. At first it made sense to have everything in a single template until you hit the maximum number of resources – 200. At this point we were forced to break our dearly loved template into independent stacks
From Puppet to Docker Containers
Bootstrapping an instance during a scale up event with Puppet turned out to be slow for us. It’s not that Puppet is slow — it just didn’t fit right in our use-case. There were too many moving parts we were getting Puppet to put together for us. This is where Docker fit right in. We create a container with the application’s executing environment and the application, check it into ECR and during a scale up event, it’s checked out by CodeDeploy and boom! – it’s up and running, ready to serve. We use standalone docker coupled with docker-compose and host networking to keep things simple and fast. This has considerably improved our confidence in AutoScaling. I could be sleeping or sitting on a beach in Goa sipping beer and AutoScaling reliably manages traffic 🙂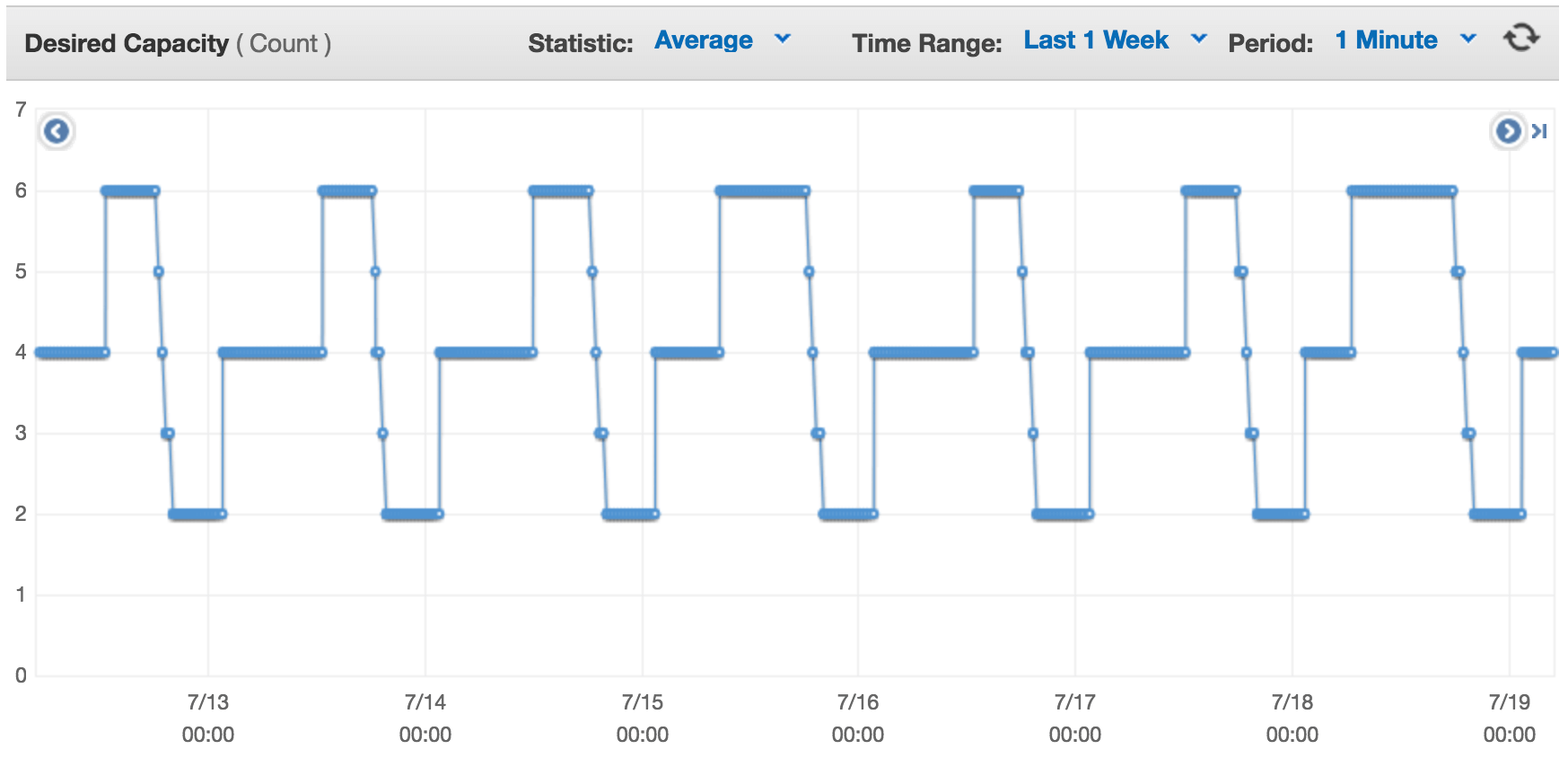
From Freestyle Jenkins Jobs to Scripted Pipelines to Declarative Multi-branch Pipeline Jobs
Our journey with Jenkins begun with freestyle jobs — the ones where you put in shell commands and it reliably executes them, every single time. We had two jobs per application, one to build and the other to deploy. Of course, this is no CI/CD. Since then, we’ve moved to scripted pipeline jobs. This was a step in the right direction, code and Jenkins instructions lived together. More importantly, job configuration was versioned controlled. In our latest iteration, we have moved from scripted to declarative multi pipeline jobs. Most of the heavy lifting is done in libraries. This gives us clean looking Jenkins files which are easier to read and understand by a larger audience.
From SSH Loops for Deployment to CodeDeploy
Deploys were handled by bash for-loops that ran commands on remote hosts after querying the AWS API for available hosts. This worked surprisingly very well for more than two years. It never failed on us. Team members would build, deploy and sometimes revert multiple times a day. But as we grew we needed funky things like – deploy to all at once and deploy to a percentage of hosts at once. Besides going multi data center, this was going to be difficult to manage. We needed something that natively understood instance states and hooked into AutoScaling lifecycle hooks.
AWS CodeDeploy is our new hero. It integrates nicely with other AWS services.
The one thing I would really like to see CodeDeploy implement is a way to hook into the startup lifecycle events for an EC2 host not in an AutoScaling group. This way when a static EC2 host comes to life, deployment groups that qualify it will trigger deployments. As a work around, we currently use the --update-outdated-instances--only flag to trigger deployments to new instances. This still involves us having to trigger deployments instead of some way to magically hook into the instance start lifecycle.
From Nagios to Sensu
Puppet would export virtual resources as a part of bootstrap that would apply on the Nagios server. There was just too much of an overhead to add a client. Coupled with AutoScaling where instances (client in Nagios’ scheme of things) are short lived meant that we had to keep re-generating Nagios configuration everytime an instance was terminated or came to life. This, and the need for a REST API drew us to Sensu. It allows clients to be dynamically added and handlers can delete clients using API if it’s terminated by AutoScaling
PS: We made the jump to Sensu a while ago. I have added it here to document it, since it represents a major change
ToDo 2017
Restricting External Network Connectivity
I am toying around with the idea of disabling outbound network connectivity from all our EC2 instances. With Docker, we have considerably reduced the number network calls we make for packages. On top of my mind, we need external network connectivity for NTP, CodeDeploy to do its work, ECR to checkout containers and access to Amazon’s package repository to install Docker. We could host an internal NTP server, use Packer to pre-package the packages we need and generate an AMI based on Amazon Linux and whitelist CodeDeploy/S3 and ECR’s IP ranges. This should get us to a point where we don’t have a route to 0.0.0.0
Automate Routine Maintenance Task with EC2 System Manager
We still have a few people logging in over SSH to do routing maintenance tasks or debugging process or data on EC2 instances. I would rather not have user accounts on EC2 instances, instead use system manger documents and run command. This allows us to audit what we are doing inside an EC2 instance, not because we don’t trust our co-workers but because audit trails help look back at everything we did during a firefight. Audit trails also keep auditors very happy
Sitting in one corner of the world, this is what we came up with. I wanted to put this out there for a larger audience to review. If you know of better ways dealing with this, do let me know in the comments below. We can discuss this in detail too.
The Intelligent Mobile Marketing Platform
Francis Pereira 
Francis Pereira, a founding member at CleverTap, leads the security and infrastructure engineering teams, focusing on infrastructure automation, security, scalability, and finops.
Free Customer Engagement Guides
Join our newsletter for actionable tips and proven strategies to grow your business and engage your customers.
