














Table of Contents
Categories
Most Popular


What a fantastic summer for sports fans! Between the Indian Premier League (IPL) cricket season and the FIFA World Cup, countless hours of riveting action have been on display for billions of sports fanatics worldwide.
As sports consumption has moved to mobile, our customers have seen huge traffic increases. And for CleverTap, that means handling unprecedented traffic ourselves.
So, while billions were enjoying streaming games, viewing scores, ordering pizzas, and fine-tuning their fantasy teams, our systems and engineers were hard at work processing billions of incoming events and outgoing push notifications.
The CleverTap architecture was designed to be scalable from day one, but the game-time, order-of-magnitude jumps in traffic definitely had us on our toes. As we reflect on the action, we thought it might be useful to recount some of our experience here (and to brag, just a little ?).
Architecture
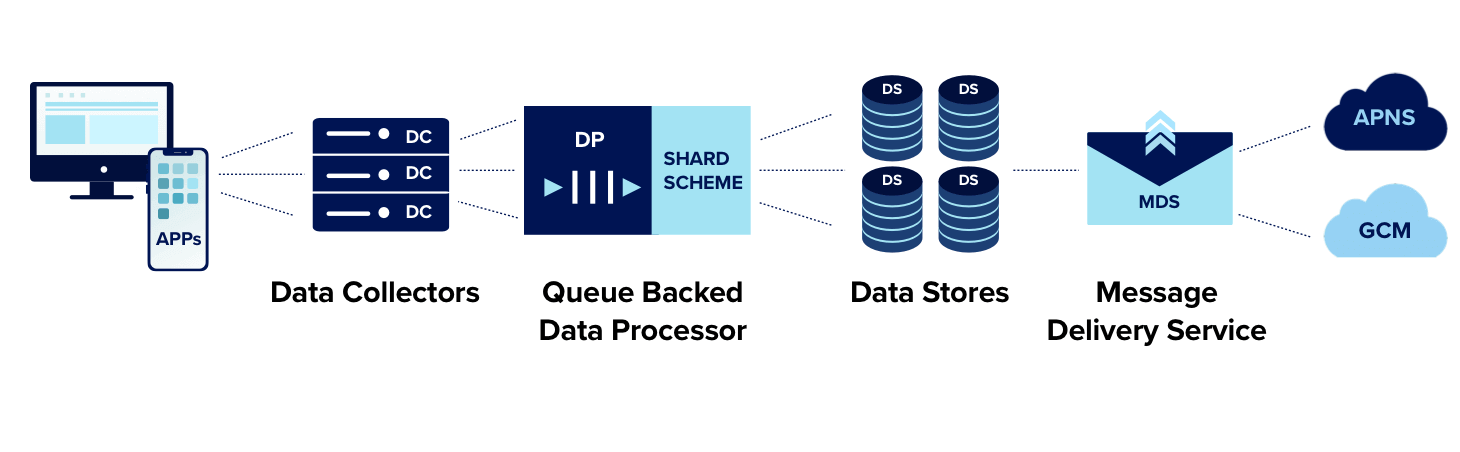
Generally speaking, our architecture consists of a Data Collection layer, fronted by AWS Elastic Load Balancers (ELBs), that accept data via HTTPS from client side SDKs (as well as our public REST API). To remain responsive, our Data Collection layer does only minimal validation before dropping data into a separate Data Processing layer for preparation and delivery to our Data Store layer, where it is immediately available for querying. A separate Message Delivery Service (MDS) is responsible for querying the Data Store to generate and deliver messages via email, push notifications, and other channels.
One of the main uses cases of our platform is to trigger messaging campaigns based on data events in real-time — think instant score alert push notifications.
So when we think about handling scale in this context, we are primarily concerned with:
- Handling data ingestion (particularly out-of-band spikes) without any processing delays so that campaigns are triggered by incoming data in real time.
- Delivering the resulting messages to users in real time.
Planning Ahead
As we approached this problem, it definitely helped that our game-time traffic-spike schedule was published months in advance. As such, we were able to start our general planning and preparation a reasonable amount of time before the start of these events and execute specific capacity planning tactics around the time of each game.
Our starting point was to simulate high traffic at the Data Collection layer from a comfortable steady-state of 200K requests per second to 1M requests per second. While our Data Collectors are in an auto-scaling group fronted by Amazon ELBs (which in theory should also auto-scale), we quickly realized auto-scaling becomes unreliable when dealing with a sudden spike of that magnitude. More often than not the ELBs would simply become non-responsive and then stop accepting requests, and our Data Collectors suffered similarly as the auto-scaling was far too slow relative to incoming traffic spikes.
As we knew the traffic schedule ahead of time, we were able to pre-provision additional capacity for Data Collectors and ELBs right before game time. In the case of the ELBs, the pre-provisioning process is called “pre-warming”. (Read more about ELB pre-warming and other best practices.)
With our Data Collection layer now functioning comfortably at ~1M requests per second, we turned our attention to our Data Processing layer.
Parallelization to the Rescue
The way we were set up, we had a dedicated queue-backed Data Processor for each account (read: app). The processing was parallelized at the account level, which meant the system scaled easily when new accounts were added and until now there was never the need to parallelize within a single account. However our assumptions broke given such high traffic during these events and we quickly saw Data Processors reaching their I/O limit, resulting in processing lag.
It became evident that we needed more processing power for an account and a single Data Processor was a bottleneck. Parallelizing processing within an account was the only way out, which required some restructuring.
Earlier Scheme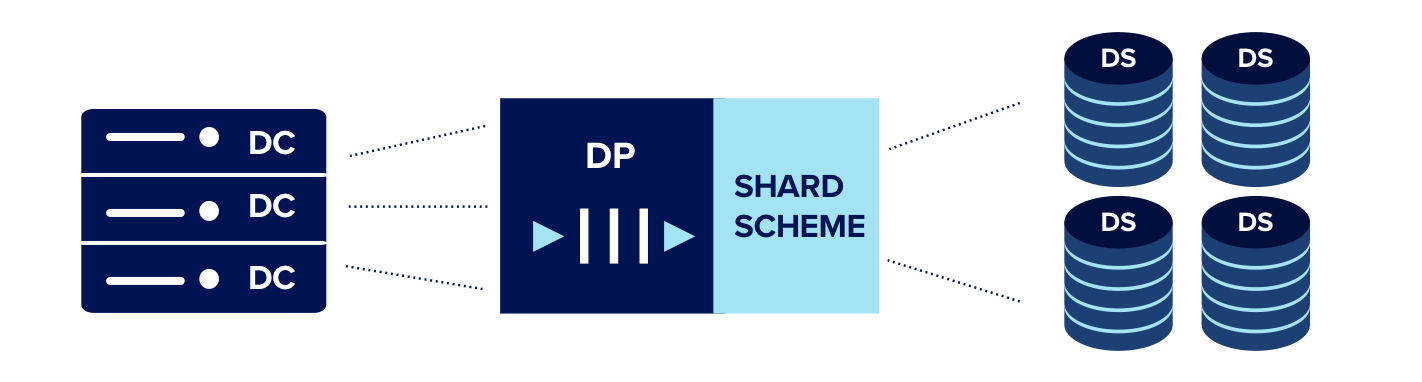
In this process of restructuring, it helped that our Data Store was already sharded for a single account. The intention of this sharding scheme was to parallelize querying performance. We now realized that we needed to pull that same shard scheme forward to our Data Processing layer. This meant a single account had multiple Data Processors mapped to it.
So instead of having a single Data Processor queue per machine serving multiple Data Store shards, we had multiple processing pipeline shards, each consisting of a Queue→Data Processor→Data Store.
New Scheme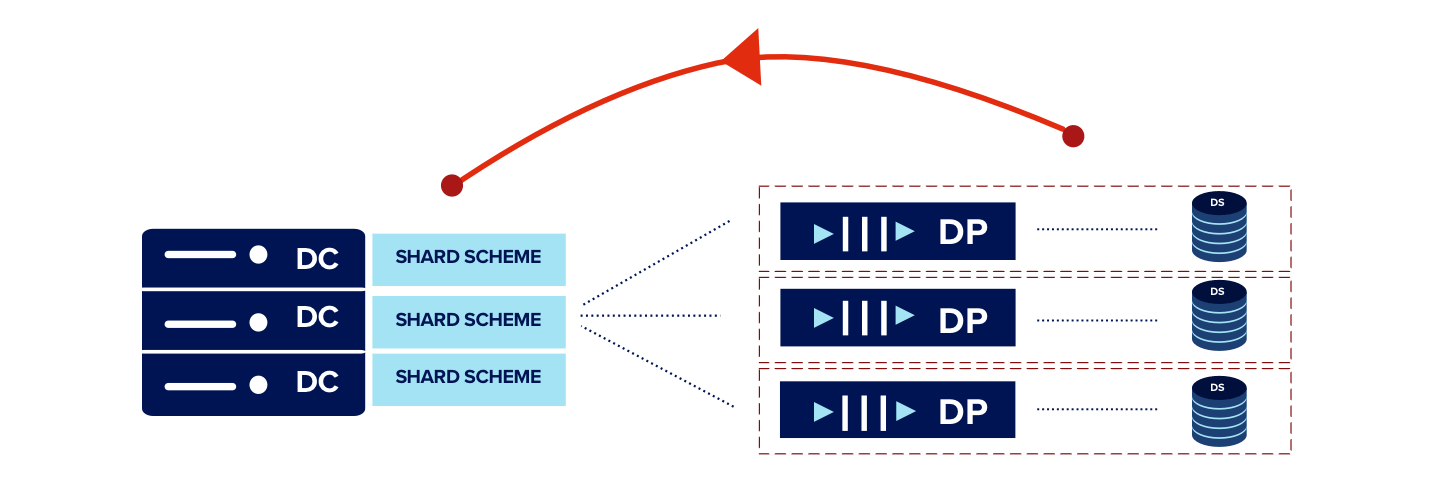
This enhancement increased our incoming processing capacity by a factor of the number of pipeline shards. If processing throughput was maxed out, all we had to do was add a new processing pipeline to relieve the pressure. Huzzah!
With consistent hashing being our shard scheme, it became fairly easy to add a new shard to the pipeline. (Read more about Consistent Hashing.)
At this point, we were in control of ingestion of data, and it was time to focus our attention to message delivery. The Message Delivery Service is responsible for this, and the service had to be really fast in delivering messages to prevent live score updates from being delayed.
The Message Delivery Service has two primary jobs:
- For a given message triggered by a campaign (in response to incoming data), query the Data Store to determine the users that would qualify for that message.
- Deliver the message to those users.
Earlier Scheme
Initially we deployed a dedicated Message Delivery Service (MDS) instance per account. However, due to the high load on Data Stores and simultaneously sending a massive number of messages, the service clogged. The system was unable to keep up with the massive message delivery requests, which led to delayed delivery times. We realized we needed more systems distributing this work which meant delivering messages in parallel.
We decided to shard our MDS instance with the same shard scheme as our Data Store. In fact, to reduce latency between the two systems, we placed the the two services on the same host. This helped to reduce total processing time as each MDS was querying a subset of data and also delivering only that set. As a result we ended up with a processing pipeline shard consisting of Queue → Data Processor → Data Store → MDS
New Scheme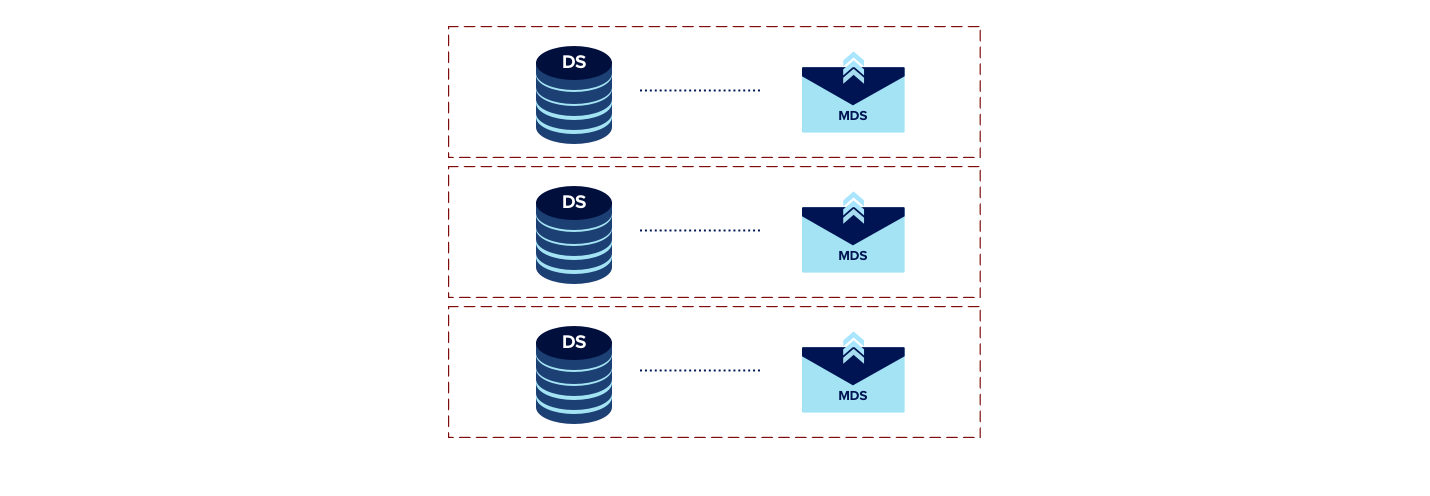
Throughput of our Message Delivery System was improved by the factor of number of processing pipeline shards.
New Processing Pipeline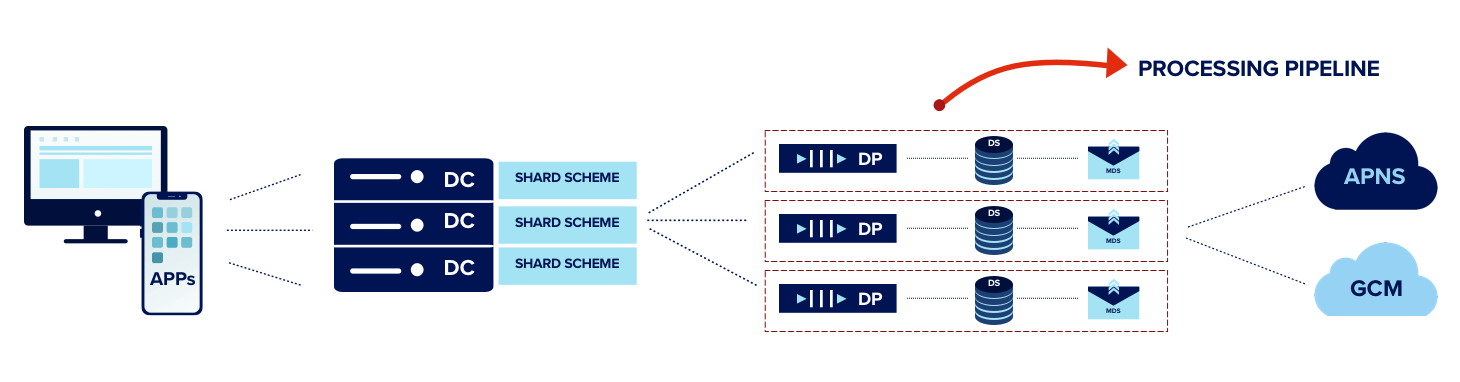
Refining Architecture for Scalability
In anticipation of record traffic spikes we ended up slightly re-architecting our systems. This exercise proved pivotal in ensuring a smooth run during these events. Our systems are now truly parallel starting from data ingestion to querying to message delivery. This enables us to break large monolithic accounts (from a traffic perspective) into several smaller accounts, giving us the ability to deal with internet scale apps.
Pranay Warke 
As a founding member of CleverTap, Pranay Warke has extensive software industry experience. As VP of Engineering, he leads teams in developing highly performant, scalable, and efficient software systems.
Free Customer Engagement Guides
Join our newsletter for actionable tips and proven strategies to grow your business and engage your customers.
