














Table of Contents
Categories
Most Popular


In preparation for compliance certification later this year, we disabled write access for all AWS console users (except the primary, more on that later) to streamline infrastructure change management. This post describes how we created a self enforcing, self documenting infrastructure change management system using Git, CodePipeline and CloudFormation.
Background
AWS CodePipeline is a service that allows you to model and visualise steps within your software delivery pipeline. For building and testing, it integrates with AWS CodeBuild – another service that provides a customisable execution environment where you can run anything arbitrary. For deployment, it integrated with AWS CodeDeploy, Amazon Elastic Container Service (ECS) and AWS CloudFormation. To perform almost any task other than the built-in integrations, there is support for Lambda
CloudFormation provides a way to describe AWS resources in simple text. It’s used for provisioning and managing all AWS resources (VPC, routing, subnets, LaunchConfigurations AutoScaling Groups etc) that are required for running your application/workload.
Why CodePipeline?
We chose CodePipeline over Jenkins (who has served us well for a very long time now) to model our CloudFormation deployment pipelines because
- In our experience, Jenkins with its pipeline DSL makes pipelines brittle. The
Jenkinsfilehas too much knowledge of the operating environment. The ability to configure pipelines in CodePipeline based on the current operating environment (stack) by passing variables around using CloudFormation makes it easier to adapt to environment specifics. This makes it easier to provision environments on the fly - It provides the ability to provision delivery pipelines from within CloudFormation along with rest of the application infrastructure
- Delivery pipelines live alongside environment provisioning code
The nuts and bolts of our change management pipeline
Any decent CloudFormation codebase is broken into multiple stacks. With each stack being responsible for one specific function (network, database, service A, service B) and represented by a single template file. We modelled one CodePipeline pipeline per CloudFormation stack. This provides the ability to execute updates to CloudFormation stacks in any order we deem necessary.
The man in the middle – GitHub to S3 synchronisation
Each pipeline was initially configured to watch our CloudFormation repository in GitHub. The downside to this is, a commit to a single file causes all the pipelines to begin executing in unison because each one detects a change in the repository. To get around this, we created a pipeline that synchronises files from GitHub to S3. Each pipeline is then configured to watch specific files (the stack’s template and configuration) in S3, instead of the whole repository in GitHub. This way, only the pipeline mapped to the specific stack executes when its template or configuration file changes. Here is what the GitHub to S3 sync pipeline looks like visually in CodePipeline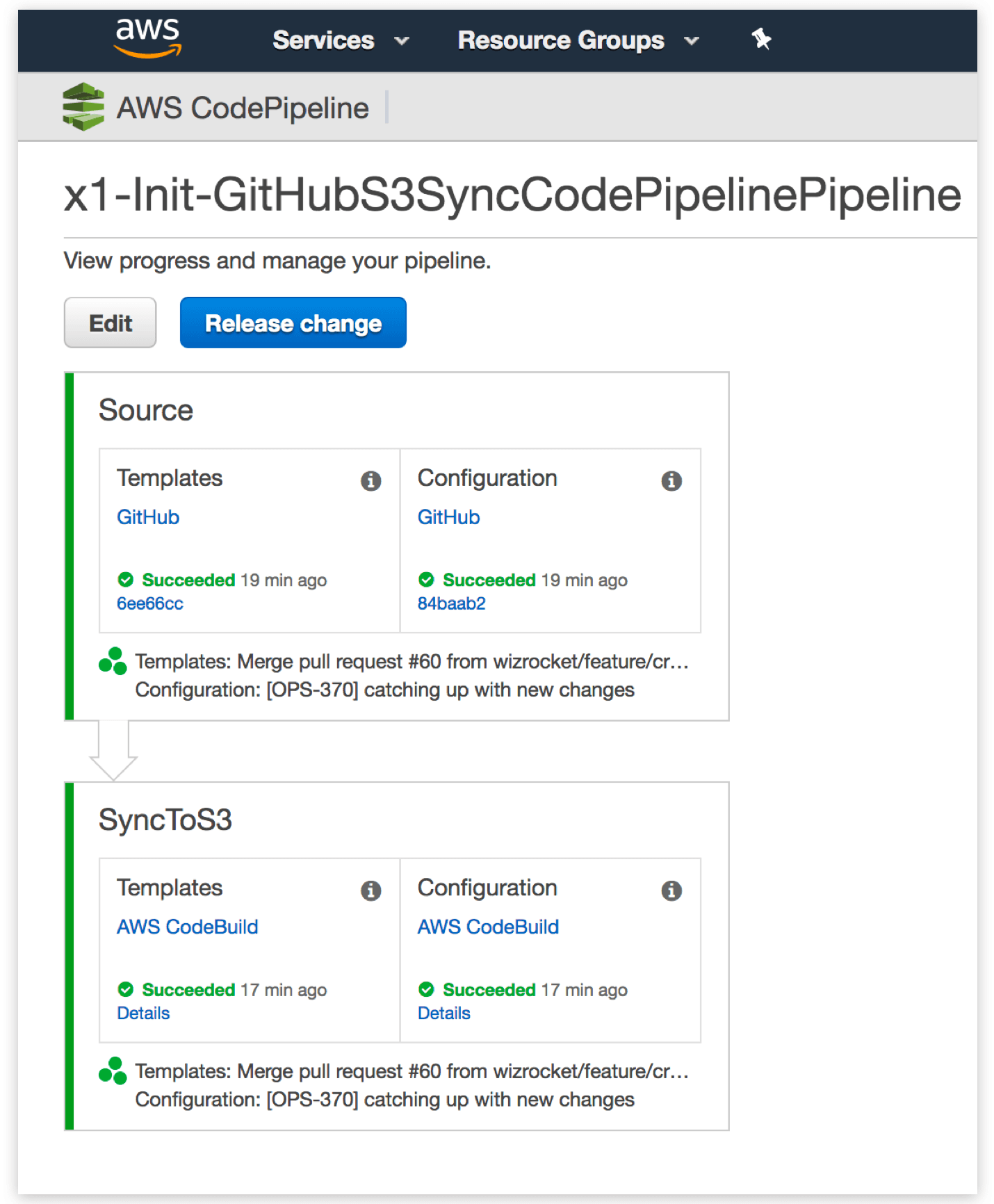
You can’t have a CodePipeline pipeline watch a file in S3, which is why we had to zip it into an archive that holds just the file to make CodePipeline happy. Here is what the buildspec.yml used by CodeBuild in the above pipeline job looks like
version: 0.2
phases:
build:
commands:
- echo Build started at `date`
- export BUILD_ROOT=${PWD}
- echo "Fetch existing template files from s3"
- mkdir -p /tmp/${SOURCE_S3_BUCKET}
- aws s3 sync --quiet --delete s3://${SOURCE_S3_BUCKET}/ /tmp/${SOURCE_S3_BUCKET}/
- echo "Comparing and pushing updated files"
- |
cd ${BUILD_ROOT}
for file in $(find stacks -name "*.json" )
do
if [ -f /tmp/${SOURCE_S3_BUCKET}/TemplateSource/${file} ]
then
if ! cmp ${file} /tmp/${SOURCE_S3_BUCKET}/TemplateSource/${file}
then
zip --junk-path ${file}.zip ${file}
aws s3 cp $file s3://${SOURCE_S3_BUCKET}/TemplateSource/${file}
aws s3 cp ${file}.zip s3://${SOURCE_S3_BUCKET}/TemplateSource/${file}.zip
fi
else
zip --junk-path ${file}.zip ${file}
aws s3 cp $file s3://${SOURCE_S3_BUCKET}/TemplateSource/${file}
aws s3 cp ${file}.zip s3://${SOURCE_S3_BUCKET}/TemplateSource/${file}.zip
fi
done
- echo "Cleaning up deleted files using reverse lookup"
- |
cd /tmp/${SOURCE_S3_BUCKET}/TemplateSource/
for file in $(find stacks -name "*.json")
do
if [ ! -f ${BUILD_ROOT}/${file} ]
then
aws s3 rm s3://${SOURCE_S3_BUCKET}/TemplateSource/${file}
aws s3 rm s3://${SOURCE_S3_BUCKET}/TemplateSource/${file}.zip
fi
done
- echo "S3 file sync completed"
post_build:
commands:
- echo Build completed at `date`
The CodePipeline pipeline
Each CodePipeline pipeline is mapped to one single stack. There are two sources for the pipeline – the template and the configuration. When a change in either of the sources is detected, the pipeline begins executing. It creates a CloudFormation changeset and notifies everyone that a changeset is awaiting review. Upon manual review of the changeset a user with IAM permission codepipeline:PutApprovalResult approves it. Upon approval, the changeset is executed.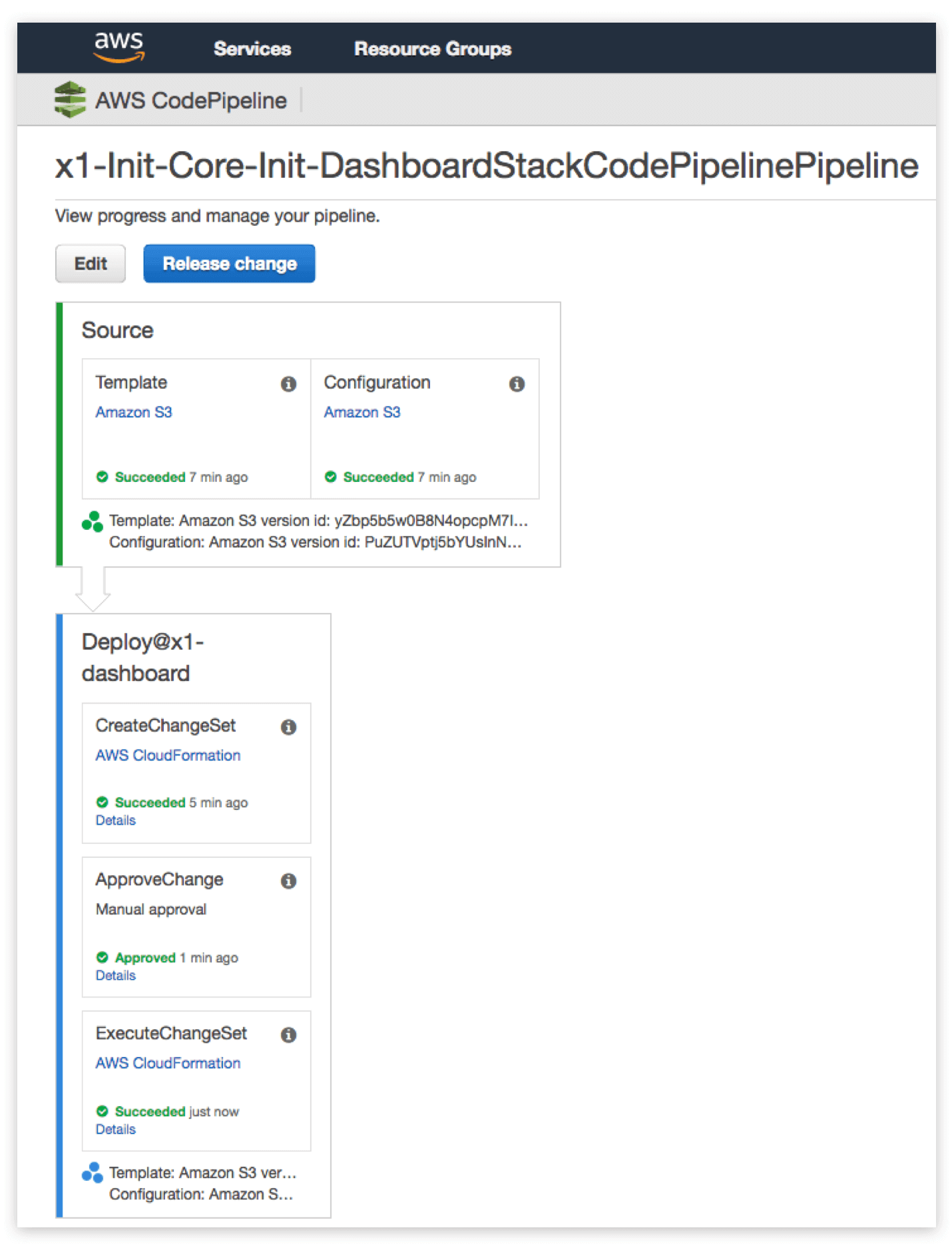
A CloudFormation stack of pipelines
We have a stack that provisions CodePipeline pipelines. These pipelines provision and manage other stacks. Yes, that sounds twisted – read it once again to wrap your head around it. This is our version of infrastructure init. Once provisioned by hand, it’s capable of provisioning all the CloudFormation stacks we need to run and manage our platform. We have multiple, 100% isolated, independent production environments deployed across various AWS regions.
A Self Enforcing, Self Documenting infrastructure change management process
The change management process begins with a branch being created for a change. This branch is tested independently by the person working on it, in his/her development AWS account owned by CleverTap. Once the change is verified in development, a pull request to merge it into develop is raised. Develop is locked using GitHub’s branch protection rules. A merge into develop requires at least one review and can only be merged by the repository owners. This is where a peer review happens and is signed off by the repository owner(s). From develop, it’s merged into master by the repository owner(s). Once in master, the CodePipeline pipeline that is watching the repository detects the change and begins executing. This causes the files that changed in master to get updated in S3. When files in S3 are updated, the pipeline(s) watching it begin executing causing the creation of a changeset and notifying everyone via email that a change needs approval before being executed. The changeset is once again reviewed by the repository owner in our case and executed by any team member during environment maintenance hours.
Assuming no one other than the root AWS account has write access, this change management process is self-enforcing. There is no way anyone can change the state of infrastructure without following the process.
Although we don’t have a use case for it, another interesting possibility is to require two different people to approve before the pipeline continues and applies the changeset.
The harmless cheating
In the opening statement, I said that we disabled write access for everyone with the root account being the exception. That’s not 100% true. Operations and engineering IAM accounts have the ability to stop, start an instance, invalidate CloudFront cache and execute/approve build pipelines. These write actions are operational requirements. They do not change the configuration of deployed infrastructure.
CodePipeline CloudFormation Gotchas
- Integer parameters in TemplateConfiguration files must be wrapped around quotes
- There is no native way to handle location for CloudFormation transforms such as
AWS::Include
Our CodePipeline wish list
CodePipeline in my head is the way forward for us. CloudFormation delivery pipelines is just the beginning. We will begin moving all our software delivery pipelines over shortly. Having said that, based on our experience with CodePipeline over the past couple of months, here’s our wish list:
- A way to disable automatic execution on pipeline provisioning.
RestartExecutionOnUpdateapplies to updates to an existing pipeline. I understand it’s neat to automatically begin execution on provisioning, because – after all, the pipeline is meant to magically deploy software to its destination. But there are cases, especially when deploying to CloudFormation where you want to control the first time execution of a pipeline. - Git source integration with providers other than GitHub, Amazon CodeCommit or S3. Git over SSH to user-defined git repositories perhaps.
- Support for IAM action
ListAllMyPipelinessimilar to S3 actionListAllMyBuckets. This will limit the pipeline listing to only the pipelines that user has access to. - Search should match pipelines that contain the searched text within the name of the pipeline.
- Add the ability to specify a stack update policy separately from
TemplateConfiguration. Access to the repository that holds template configuration is available to a larger audience. Update policy which controls stack protection information should be protected separately. - Speed up pipeline stage transition and action execution updates in the UI. Overall, pipeline UI updates and pipeline execution speed needs to improvement.
- If a pipeline is configured with multiple sources and changes to more than one source is detected during a poll interval, don’t execute the pipeline for each source change. Instead, understand that multiple sources have changed and incorporate the changes from all the sources in the next pipeline execution.
- Support
StoporCancelduring a pipeline execution. This can currently be achieved by rejecting an approval stage. But, there is a difference betweenRejectandStoppedorCancelled. - Show the execution ID of the pipeline that is currently running in the pipeline UI.
- Show last execution start and end datetime on the pipeline listing page in the console.
- Show current status (In Progress, Failed, Succeeded) on the pipeline listing page in the console.
- Pipeline creation date
More infoandWhat's newsections of the pipeline listing page don’t add value. I would rather have the information listed above so that status of all my pipelines is visible at one glance
We will lobby for our wish list with AWS and hopefully some if not all of the items on the list see the light of day.
Francis Pereira 
Francis Pereira, a founding member at CleverTap, leads the security and infrastructure engineering teams, focusing on infrastructure automation, security, scalability, and finops.
Free Customer Engagement Guides
Join our newsletter for actionable tips and proven strategies to grow your business and engage your customers.
