







Table of Contents
Categories
Most Popular




At CleverTap, we are rapidly approaching a landmark of sorts: processing 100 Billion unique monthly events and sending out tens of Billions of real-time messages monthly in response to those events. As we near this goal, we thought it would be a good time to share some of our evolution and learning as we have scaled the platform to this point.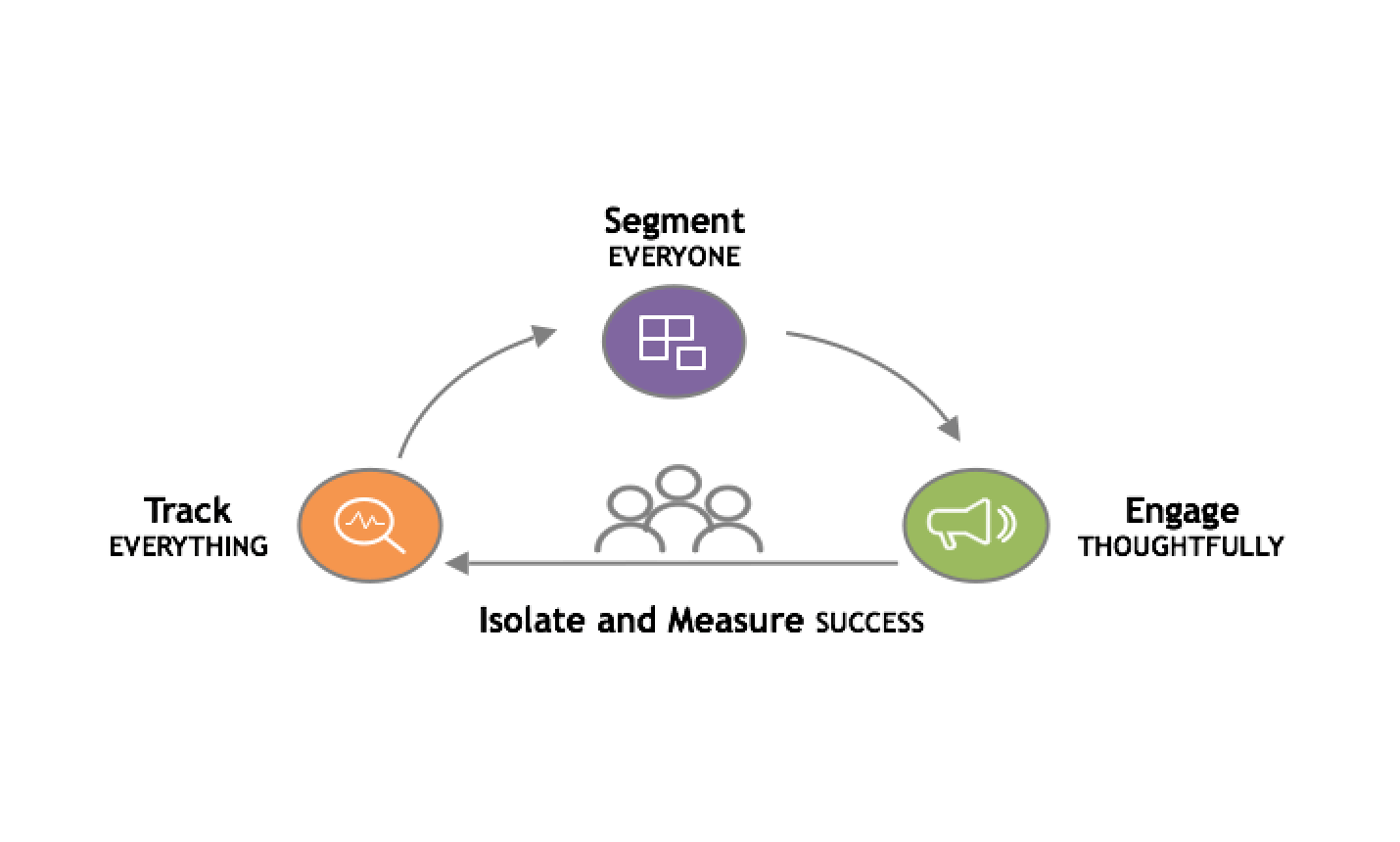
The Platform
The CleverTap platform enables the high-volume targeting and delivery of user messaging through various channels (native app push, email, web notifications, webhooks, SMS) powered by user behavioral analysis and segmentation.
To support our customers, our goal is to:
- Track Everything: efficiently ingest, store and query billions of user events and profiles.
- Segment Everyone: flexibly and time-efficiently query that data to surface insights on user behavior and identify/target important segments of users.
- Engage Thoughtfully: facilitate the high-volume delivery of individual user-specific, contextually-relevant messages based on that user understanding/segmentation.
All the while providing a cost effective solution.
The Architecture
We operate primarily on two forms of data:
- User actions (aka events) in customer applications (e.g., Product Searched -> Added to Cart -> Purchased), and
- Individual user profile characteristics (e.g, Customer Type = Gold, Birthday = January 1, 1990).
Layered on top of this data is our Segmentation Engine, which encapsulates the query capability to execute real-time analysis, identification and presentation of user behavioral segments.
Our Notification Delivery System is responsible for sending targeted messages that are triggered for the desired user segments. These could be personalized based on the user behavior and attributes – like name, product viewed, etc.
Historically, we relied on third-party, open source tools (e.g. Hadoop, MongoDB) for significant components of our data layer. But, pretty early on we realized that meeting our cost, flexibility and speed goals could only be achieved with the raw data residing 100% in-memory.
With that guiding principle in mind, we have now fully transitioned to a custom in-house, 100% in-memory data store (with obsessive persistence to disk and external storage backup).
Moving to an in-house solution allowed us to:
- prioritize query speed/flexibility,
- make optimizations based on the particular structure of our data, something more generic tools could not do, and
- increase control over how our data is stored.
Our Data Store implementation focused around 3 core strategies:
- Data compression
- Parallelization
- Putting our code where the data is
Data compression
Both event and profile data undergo dictionary encoding to optimise space utilisation. Chunks of sequential event data are further block compressed (LZ4).
Dictionary encoding is a powerful lossless compression technique that looks for repeating patterns of strings, assigns each of them a unique identifier, and uses this identifier in place of the verbose string while storing information. In our system, we accept name-value pairs for user profile and event properties (e.g., for a Purchased event, property Item = Frodo’s Ring). Logic dictates that property names would be more or less same for the same kind of event, and we find that property values are also frequently duplicated for certain events – as a result, dictionary encoding provides us with a storage reduction of 3x.
Block compression. We store sequences of immutable event data in byte array chunks, and applying LZ4 compression on a per chunk basis on top of dictionary encoding gave us a further 3x reduction in storage requirements without significant CPU and time overheads. Our benchmarks indicated LZ4 was the compression algorithm of choice owing to its fast compression and decompression speeds and healthy compression ratio.
Parallelization
For large accounts, data is sharded across a cluster based on a unique identifier such that one user’s data resides on one physical host. This allows us to apply MapReduce techniques to compute query results in parallel on each shard and then aggregate them to obtain a final output.
We also apply resharding techniques to support cost-effective cluster growth. Resharding refers to the process of adding more physical hosts to a cluster when it grows beyond provisioned capacity, and correspondingly redistributing data.
In our scenario, let’s assume for a significant customer we initially provision 10 physical hosts each having 32 GB memory based on anticipated capacity of 300 GB with some breathing room. As the account grows organically over time, their dataset begins to exceed the limit and is expected to grow to 350 GB. Now, since our hosting provider provisions memory optimized boxes in powers of two, we are left with two options — double each of the 10 boxes to 64 GB, overprovision by about 290 GB (640 – 350); or reshard to 12 hosts each with 32 GB capacity to give us a total capacity of 384 GB.
To accomplish resharding we need to efficiently move data between host machines. A variant of consistent hashing worked really well for us in minimizing the data movement across shards.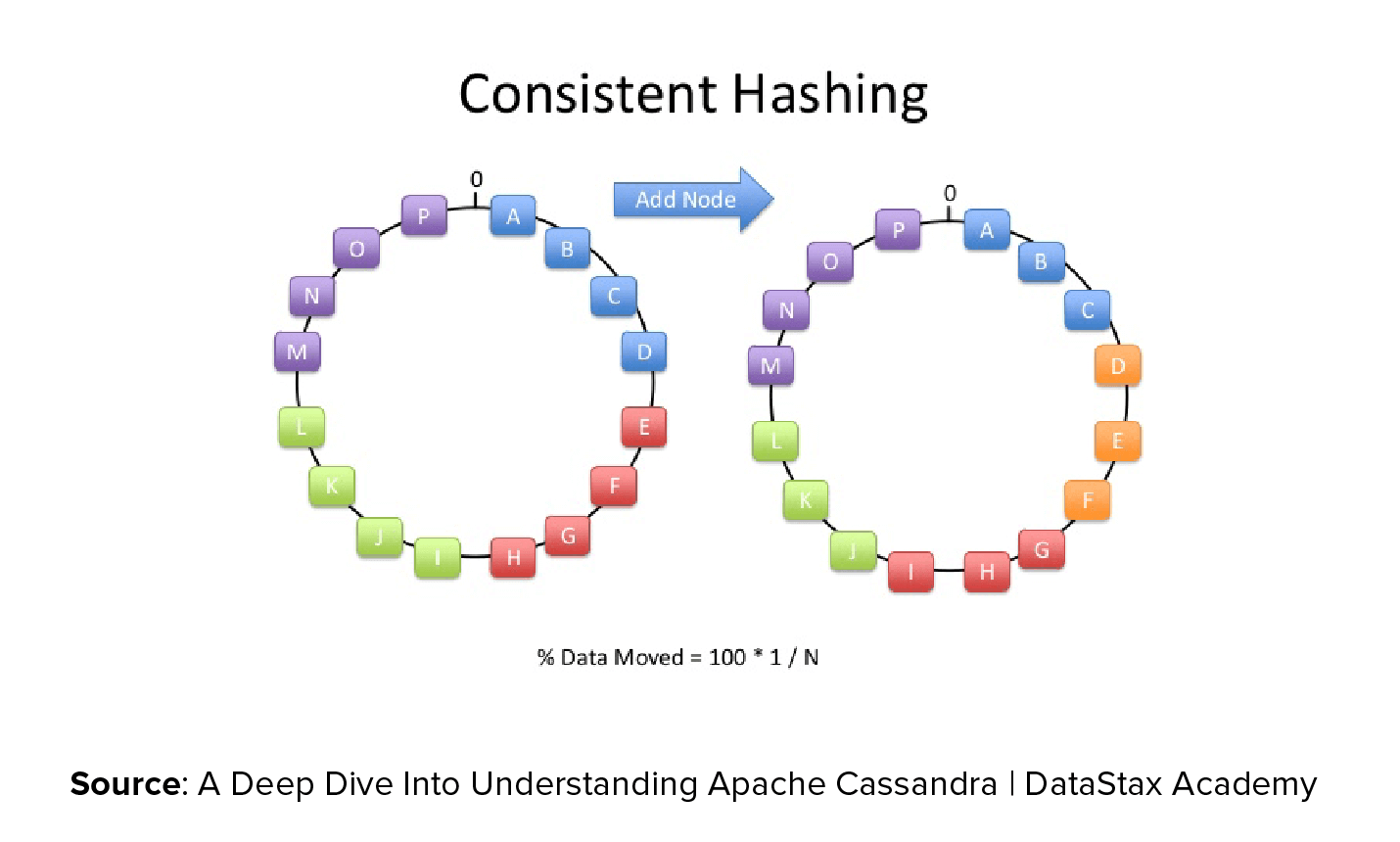
The end result is that we’re able to visualize large data sets as groups of smaller sets, enabling massive parallelization in both analytics computing and message delivery.
Putting our code where the data is
The Notification Delivery System queries the Data Store quite heavily to obtain the currently qualified set of users for each messaging campaign. To reduce latency, we typically run the Notification Delivery System on the same physical host as the Data Store. In this regard, Docker greatly helps us in isolating the two processes from one another while still providing a shared workspace for efficient exchange of files.
The Future
At this point, we feel great about the flexibility, speed and cost-effectiveness of our platform as we look forward to handling the next 100 Billion events.
Beyond that, we’re excited about the power this architecture gives us to accelerate our roadmap for launching discovery enablement (e.g. automatic trend identification/visualization) and prescriptive analytics (e.g. suggesting, and presenting the implications of, decision options to capitalize on predicted outcomes) tools on the platform.
On the discovery enablement front, check out our recently introduced Pivots (automatically see trends and outliers in a unified view) and Flows (visualize how users traverse your application) tools – much more to come there. As for prescriptive analytics, we’ll have a number of exciting things to share with you in the coming months.
Stay tuned!
The Intelligent Mobile Marketing Platform
Mohit Minhas 
Leads Competitive and Market Intelligence. Expert in cross-channel marketing strategies & platforms.
Free Customer Engagement Guides
Join our newsletter for actionable tips and proven strategies to grow your business and engage your customers.
